It is late on Friday afternoon, and John is about to implement the last feature of the sprint. He is developing an agile software management system, and this final feature supports developers during planning poker.
Planning poker is a popular agile estimation technique. In a planning poker session, developers estimate the effort required to build a specific feature of the backlog. After the team discusses the feature, each developer gives an estimate: a number ranging from one to any number the team defines. Higher numbers mean more effort to implement the feature. For example, a developer who estimates that a feature is worth eight points expects it to take four times more effort than a developer who estimates the feature to be worth two points.
The developer with the smallest estimate and the developer with the highest estimate explain their points of view to the other members of the team. After more discussion, the planning poker repeats until the team members agree about how much effort the feature will take. You can read more about the planning poker technique in Kanban in Action by Marcus Hammarberg and Joakim Sundén (2014).
John is about to implement the feature’s core method. This method receives a list of estimates and produces, as output, the names of the two developers who should explain their points of view. This is what he plans to do:
The method should receive a list of developers and their respective estimates and return the two developers with the most extreme estimates.
Input: A list of Estimates, each containing the name of the developer and their estimate
Output: A list of Strings containing the name of the developer with the lowest estimate and the name of the developer with the highest estimate
After a few minutes, John ends up with the code in the following listing.
Listing 1.1 The first PlanningPoker implementation
public class PlanningPoker {
public List<String> identifyExtremes(List<Estimate> estimates) {
Estimate lowestEstimate = null; ❶
Estimate highestEstimate = null; ❶
for(Estimate estimate: estimates) {
if(highestEstimate == null ||
estimate.getEstimate() > highestEstimate.getEstimate()) { ❷
highestEstimate = estimate;
}
else if(lowestEstimate == null ||
estimate.getEstimate() < lowestEstimate.getEstimate()) { ❸
lowestEstimate = estimate;
}
}
return Arrays.asList( ❹
lowestEstimate.getDeveloper(),
highestEstimate.getDeveloper()
);
}
}❶ Defines placeholder variables for the lowest and highest estimates
❷ If the current estimate is higher than the highest estimate seen so far, we replace the previous highest estimate with the current one.
❸ If the current estimate is lower than the lowest estimate seen so far, we replace the previous lowest estimate with the current one.
❹ Returns the developers with the lowest and the highest estimates
The logic is straightforward: the algorithm loops through all the developers in the list and keeps track of the highest and lowest estimates. It returns the names of the developers with the lowest and highest estimates. Both lowestEstimate and highestEstimate are initialized with null and later replaced by the first estimate within the for loop.
Generalizing from the code examples
Experienced developers may question some of my coding decisions. Maybe this Estimate class is not the best way to represent developers and their estimates. Maybe the logic to find the smallest and highest estimates is not the best. Maybe the if statements could be simpler. I agree. But my focus in this book is not object-oriented design or the best ways to write code: rather, I want to focus on how to test the code once it’s written.
The techniques I show you throughout this book will work regardless of how you implement your code. So, bear with me when you see a piece of code that you think you could do better. Try to generalize from my examples to your own code. In terms of complexity, I am sure you have encountered code like that in listing 1.1.
John is not a fan of (automated) software testing. As is commonly done by developers who do not automate their tests, John runs the finished application and tries a few inputs. You can see one of these trials in figure 1.1. John sees that given the input in the figure (the estimates of Ted, Barney, Lily, and Robin), the program produces the correct output.
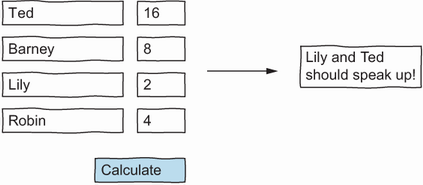
Figure 1.1 John does some manual testing before releasing the application.
John is happy with the results: his implementation worked from the beginning. He pushes his code, and the new feature is deployed automatically to customers. John goes home, ready for the weekend—but not even an hour later, the help desk starts to get e-mails from furious customers. The software is producing incorrect outputs!
John goes back to work, looks at the logs, and quickly identifies a case where the code fails. Can you find the input that makes the program crash? As illustrated in figure 1.2, if the developers’ estimates are (by chance) in ascending order, the program throws a null pointer exception.
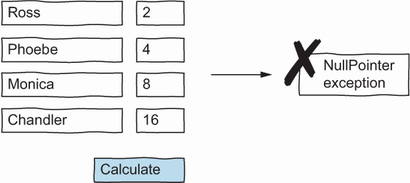
Figure 1.2 John finds a case where his implementation crashes.
It does not take John long to find the bug in his code: the extra else in listing 1.1. In the case of ascending estimates, that innocent else causes the program to never replace the lowestEstimate variable with the lowest estimate in the list, because the previous if is always evaluated to true.
John changes the else if to an if, as shown in listing 1.2. He then runs the program and tries it with the same inputs. Everything seems to work. The software is deployed again, and John returns home, finally ready to start the weekend.
Listing 1.2 The bug fix in the PlanningPoker implementation
if(highestEstimate == null ||
estimate.getEstimate() > highestEstimate.getEstimate()) {
highestEstimate = estimate;
}
if(lowestEstimate == null || ❶
estimate.getEstimate() < lowestEstimate.getEstimate()) {
lowestEstimate = estimate;
}❶ We fixed the bug here by replacing the “else if” with an “if”.
You may be thinking, “This was a very easy bug to spot! I would never make such a mistake!” That may be true. But in practice, it is hard to keep tabs on everything that may happen in our code. And, of course, it is even more difficult when the code is complex. Bugs happen not because we are bad programmers but because we program complicated things (and because computers are more precise than humans can be).
Let’s generalize from John’s case. John is a very good and experienced developer. But as a human, he makes mistakes. John performed some manual testing before releasing his code, but manual testing can only go so far, and it takes too long if we need to explore many cases. Also, John did not follow a systematic approach to testing—he just tried the first few inputs that came to mind. Ad hoc methods like “follow your instincts” may lead us to forget corner cases. John would greatly benefit from (1) a more systematic approach for deriving tests, to reduce the chances of forgetting a case; and (2) test automation, so he does not have to spend time running tests manually.
Now, let’s replay the same story, but with Eleanor instead of John. Eleanor is also a very good and experienced software developer. She is highly skilled in software testing and only deploys once she has developed a strong test suite for all the code she writes.
Suppose Eleanor writes the same code as John (listing 1.1). She does not do test-driven development (TDD), but she does proper testing after writing her code.
NOTE In a nutshell, TDD means writing the tests before the implementation. Not using TDD is not a problem, as we discuss in chapter 8.
Eleanor thinks about what the identifyExtremes method does. Let’s say her reasoning is the same as John’s. She first focuses on the inputs of this method: a list of Estimates. She knows that whenever a method receives a list, there are several cases to try: a null list, an empty list, a list with one element, and a list with multiple elements. How does she know that? She read this book!
Eleanor reflects on the first three cases (null, empty, single element), considering how this method will fit in with the rest of the system. The current implementation would crash in these cases! So, she decides the method should reject such inputs. She goes back to the production code and adds some validation code as follows.
Listing 1.3 Adding validation to prevent invalid inputs
public List<String> identifyExtremes(List<Estimate> estimates) {
if(estimates == null) { ❶
throw new IllegalArgumentException("estimates cannot be null");
}
if(estimates.size() <= 1) { ❷
throw new IllegalArgumentException("there has to be more than 1
➥ estimate in the list");
}
// continues here...
}❶ The list of estimates cannot be null.
❷ The list of estimates should contain more than one element.
Although Eleanor is sure that the method now handles these invalid inputs correctly (it is clear in the code), she decides to write an automated test that formalizes the test case. This test will also prevent future regressions: later, if another developer does not understand why the assertions are in the code and removes them, the test will ensure that the mistake is noticed. The following listing shows the three test cases (note that, for now, I am making the tests verbose so they are easy to understand).
Listing 1.4 Test cases for null, an empty list, and a one-element list
public class PlanningPokerTest {
@Test
void rejectNullInput() {
assertThatThrownBy( ❶
() -> new PlanningPoker().identifyExtremes(null)
).isInstanceOf(IllegalArgumentException.class); ❷
}
@Test
void rejectEmptyList() {
assertThatThrownBy(() -> { ❸
List<Estimate> emptyList = Collections.emptyList(); ❸
new PlanningPoker().identifyExtremes(emptyList); ❸
}).isInstanceOf(IllegalArgumentException.class); ❸
}
@Test
void rejectSingleEstimate() {
assertThatThrownBy(() -> { ❹
List<Estimate> list = Arrays.asList(new Estimate("Eleanor", 1)); ❹
new PlanningPoker().identifyExtremes(list); ❹
}).isInstanceOf(IllegalArgumentException.class); ❹
}
}❶ Asserts that an exception happens when we call the method
❷ Asserts that this assertion is an IllegalArgumentException
❸ Similar to the earlier test, ensures that the program throws an exception if an empty list of estimates is passed as input
❹ Ensures that the program throws an exception if a list with a single estimate is passed
The three test cases have the same structure. They all invoke the method under test with an invalid input and check that the method throws an IllegalArgumentException. This is common assertion behavior in Java. The assertThatThrownBy method provided by the AssertJ library (https://assertj.github.io/doc/) enables us to assert that the method throws an exception. Also note the isInstanceOf method, which allows us to assert that a specific type of exception is thrown.
If you are not familiar with Java, the lambda syntax () -> is basically an inline code block. This may be clearer in the second test, rejectEmptyList(), where { and } delimit the block. The testing framework will run this block of code and, if an exception happens, will check the type of the exception. If the exception type matches, the test will pass. Note that this test fails if the exception is not thrown—after all, having an exception is the behavior we expect in this case.
NOTE If you are new to automated tests, this code may make you nervous. Testing exceptions involves some extra code, and it is also an “upside-down” test that passes if the exception is thrown! Don’t worry—the more you see test methods, the better you will understand them.
With the invalid inputs handled, Eleanor now focuses on the good weather tests: that is, tests that exercise the valid behavior of the program. Looking back at Eleanor’s test cases, this means passing lists of estimates with more than one element. Deciding how many elements to pass is always challenging, but Eleanor sees at least two cases: a list with exactly two elements and a list with more than two elements. Why two? A list with two elements is the smallest for which the method should work. There is a boundary between a list with one element (which does not work) and two elements (which does work). Eleanor knows that bugs love boundaries, so she decides to also have a dedicated test for it, illustrated in listing 1.5.
This resembles a more traditional test case. We define the input value we want to pass to the method under test (in this case, a list with two estimates); we invoke the method under test with that input; and, finally, we assert that the list returns the two developers we expect.
Listing 1.5 Test case for a list with two elements
@Test
void twoEstimates() {
List<Estimate> list = Arrays.asList( ❶
new Estimate("Mauricio", 10),
new Estimate("Frank", 5)
);
List<String> devs = new PlanningPoker() ❷
.identifyExtremes(list);
assertThat(devs) ❸
.containsExactlyInAnyOrder("Mauricio", "Frank");
}
@Test
void manyEstimates() {
List<Estimate> list = Arrays.asList( ❹
new Estimate("Mauricio", 10),
new Estimate("Arie", 5),
new Estimate("Frank", 7)
);
List<String> devs = new PlanningPoker()
.identifyExtremes(list); ❺
assertThat(devs) ❻
.containsExactlyInAnyOrder("Mauricio", "Arie");
}❶ Declares a list with two estimates
❷ Calls the method we want to test: identifyExtremes
❸ Asserts that the method correctly returns the two developers
❹ Declares another list of estimates, now with three developers
❺ Again calls the method under test
❻ Asserts that it returns the two correct developers: Mauricio and Arie
Before we continue, I want to highlight that Eleanor has five passing tests, but the else if bug is still there. Eleanor does not know about it yet (or, rather, has not found it). However, she knows that whenever lists are given as input, the order of the elements may affect the algorithm. Therefore, she decides to write a test that provides the method with estimates in random order. For this test, Eleanor does not use example-based testing (tests that pick one specific input out of many possible inputs). Rather, she goes for a property-based test, as shown in the following listing.
Listing 1.6 Property-based testing for multiple estimates
@Property ❶
void inAnyOrder(@ForAll("estimates") List<Estimate> estimates) { ❷
estimates.add(new Estimate("MrLowEstimate", 1)); ❸
estimates.add(new Estimate("MsHighEstimate", 100)); ❸
Collections.shuffle(estimates); ❹
List<String> dev = new PlanningPoker().identifyExtremes(estimates);
assertThat(dev) ❺
.containsExactlyInAnyOrder("MrLowEstimate", "MsHighEstimate");
}
@Provide ❻
Arbitrary<List<Estimate>> estimates() {
Arbitrary<String> names = Arbitraries.strings()
.withCharRange('a', 'z').ofLength(5); ❼
Arbitrary<Integer> values = Arbitraries.integers().between(2, 99); ❽
Arbitrary<Estimate> estimates = Combinators.combine(names, values)
.as((name, value) -> new Estimate(name, value)); ❾
return estimates.list().ofMinSize(1); ❿
}❶ Makes this method a property-based test instead of a traditional JUnit test
❷ The list that the framework provides will contain randomly generated estimates. This list is generated by the method with the name that matches the string “estimates” (declared later in the code).
❸ Ensures that the generated list contains the known lowest and highest estimates
❹ Shuffles the list to ensure that the order does not matter
❺ Asserts that regardless of the list of estimates, the outcome is always MrLowEstimate and MsHighEstimate
❻ Method that provides a random list of estimates for the property-based test
❼ Generates random names of length five, composed of only lowercase letters
❽ Generates random values for the estimates, ranging from 2 to 99
❾ Combines them, thus generating random estimates
❿ Returns a list of estimates with a minimum size of 1 (and no constraint for how big the list can be)
In property-based testing, our goal is to assert a specific property. We discuss this in more detail later in chapter 5, but here is a short explanation. The estimates() method returns random Estimates. We define that an estimate has a random name (for simplicity, of length five) and a random estimate that varies from 2 to 99. The method feeds lists of Estimates back to the test method. The lists all have at least one element. The test method then adds two more estimates: the lowest and the highest. Since our list only has values between 2 and 99, we ensure the lowest and highest by using the values 1 and 100, respectively. We then shuffle the list so order does not matter. Finally, we assert that no matter what the list of estimates contains, MrLowEstimate and MsHighEstimate are always returned.
The property-based testing framework runs the same test 100 times, each time with a different combination of estimates. If the test fails for one of the random inputs, the framework stops the test and reports the input that broke the code. In this book, we use the jqwik library, but you can easily find a property-based testing framework for your language.
To Eleanor’s surprise, when she runs this property-based test, it fails! Based on the example provided by the test, she finds that the else if is wrong and replaces it with a simple if. The test now passes.
Eleanor decides to delete the manyEstimates test, as the new property-based testing replaces it. Whether to delete a duplicate test is a personal decision; you could argue that the simple example-based test is easier to understand than the property-based test. And having simple tests that quickly explain the behavior of the production code is always beneficial, even if it means having a little duplication in your test suite.
Next, Eleanor remembers that in lists, duplicate elements can also break the code. In this case, this would mean developers with the same estimate. She did not consider this case in her implementation. She reflects on how this will affect the method, consults with the product owner, and decides that the program should return the duplicate developer who appears first in the list.
Eleanor notices that the program already has this behavior. Still, she decides to formalize it in the test shown in listing 1.7. The test is straightforward: it creates a list of estimates in which two developers give the same lowest estimate and two other developers give the same highest estimate. The test then calls the method under test and ensures that the two developers who appear earlier in the list are returned.
Listing 1.7 Ensuring that the first duplicate developer is returned
@Test
void developersWithSameEstimates() {
List<Estimate> list = Arrays.asList( ❶
new Estimate("Mauricio", 10),
new Estimate("Arie", 5),
new Estimate("Andy", 10),
new Estimate("Frank", 7),
new Estimate("Annibale", 5)
);
List<String> devs = new PlanningPoker().identifyExtremes(list);
assertThat(devs) ❷
.containsExactlyInAnyOrder("Mauricio", "Arie");
}❶ Declares a list of estimates with repeated estimate values
❷ Asserts that whenever there are repeated estimates, the developer who appears earlier in the list is returned by the method
But, Eleanor thinks, what if the list only contains developers with the same estimates? This is another corner case that emerges when we systematically reflect on inputs that are lists. Lists with zero elements, one element, many elements, different values, and identical values are all common test cases to engineer whenever lists are used as inputs.
She talks to the product owner again. They are surprised that they did not see this corner case coming, and they request that in this case, the code should return an empty list. Eleanor changes the implementation to reflect the new expected behavior by adding an if statement near the end of the method, as in the following listing.
Listing 1.8 Returning an empty list if all estimates are the same
public List<String> identifyExtremes(List<Estimate> estimates) {
if(estimates == null) {
throw new IllegalArgumentException("Estimates
➥ cannot be null");
}
if(estimates.size() <= 1) {
throw new IllegalArgumentException("There has to be
➥ more than 1 estimate in the list");
}
Estimate lowestEstimate = null;
Estimate highestEstimate = null;
for(Estimate estimate: estimates) {
if(highestEstimate == null ||
estimate.getEstimate() > highestEstimate.getEstimate()) {
highestEstimate = estimate;
}
if(lowestEstimate == null ||
estimate.getEstimate() < lowestEstimate.getEstimate()) {
lowestEstimate = estimate;
}
}
if(lowestEstimate.equals(highestEstimate)) ❶
return Collections.emptyList();
return Arrays.asList(
lowestEstimate.getDeveloper(),
highestEstimate.getDeveloper()
);
}❶ If the lowest and highest estimate objects are the same, all developers have the same estimate, and therefore we return an empty list.
Eleanor then writes a test to ensure that her implementation is correct.
Listing 1.9 Testing for an empty list if the estimates are all the same
@Test
void allDevelopersWithTheSameEstimate() {
List<Estimate> list = Arrays.asList( ❶
new Estimate("Mauricio", 10),
new Estimate("Arie", 10),
new Estimate("Andy", 10),
new Estimate("Frank", 10),
new Estimate("Annibale", 10)
);
List<String> devs = new PlanningPoker().identifyExtremes(list);
assertThat(devs).isEmpty(); ❷
}❶ Declares a list of estimates, this time with all the developers having the same estimate
❷ Asserts that the resulting list is empty
Eleanor is now satisfied with the test suite she has engineered from the requirements. As a next step, she decides to focus on the code itself. Maybe there is something that no tests are exercising. To help her in this analysis, she runs the code coverage tool that comes with her IDE (figure 1.3).

Figure 1.3 The result of the code coverage analysis done by my IDE, IntelliJ. All lines are covered.
All the lines and branches of the code are covered. Eleanor knows that tools are not perfect, so she examines the code for other cases. She cannot find any, so she concludes that the code is tested enough. She pushes the code and goes home for the weekend. The code goes directly to the customers. On Monday morning, Eleanor is happy to see that monitoring does not report a single crash.
Leave a Reply